辗转了政务、医疗等多个行业后,多数隐私计算公司最终还是选择将金融业作为优先落地的行业,理由很简单:作为国内数据化程度最高的行业之一,金融业有着最为成熟的技术基础、最强烈的数据场景需求以及雄厚的购买实力。
金融业也不负众望,去年下半年以来先后落地了数十个隐私计算项目,反向印证了上述观点。但是繁华背后存隐患:我们看到,上述落地案例中实验、探索项目居多,至今还没有真正上生产环境的案例出现。
其中原因有很多,从供给侧看,隐私行业的打法、产品性能与质量等方面存在这不小问题,笔者在《隐私计算公司开拓金融业的意见与建议》、《隐私计算的破局之道》等文章中有过深入分析,不再赘述。此次我们重点从需求侧分析银行等金融机构的疑虑和担心——对既有风控技术框架的调整与改在成本。
银行传统风控技术框架
通常来讲,金融机构风控技术架构的设计思路见下图:“数据服务平台”是外部数据调用平台,承载与外部数据的统一报送与采集功能。为了方便风控建模,银行一般会单独设立针对性的风控集市用于模型训练和预测,不同目的的模型其风控集市差异较大,比如小微企业贷款与个人消费贷款的集市维度连主键信息都不一样,甚至更细致的,个人消费贷款的贷前信用评分卡模型和贷后风险表现模型也会分别建立集市进行支持。
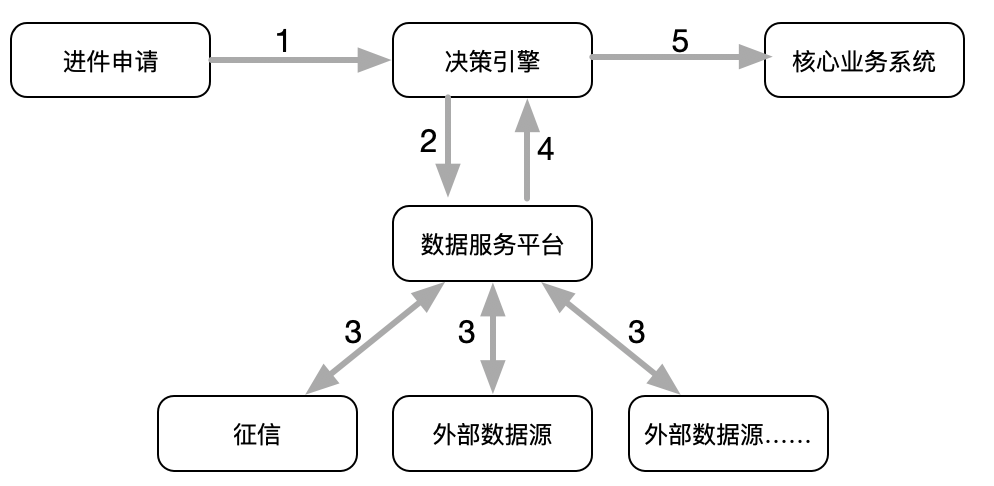
我们知道,风控模型分为模型训练和模型预测(模型运行)两个阶段。
模型训练阶段是事前、非实时的,一般是先从数据集市中的存量数据按照一定规则提炼样本,按照主键信息从数据源接口批量查得结果后,结合数据集市中银行已有的数据特征值一同建模,模型训练成型后部署在决策引擎之中,准备上生产。
在模型预测(模型运行)时,从进件前端或是核心系统传输来的进件申请将客户主键信息推动至决策引擎,引擎实时掉起数据集市和数据服务平台中入模数据的API接口查得数据,一同进入模型中生成模型结果。然后,决策引擎根据核心系统需要展示的决策结果,将各类模型结果打包形成决策包后,统一推送至核心系统及进件前端进行展示。这便是最简单的模型训练、预测的全流程。

隐私计算重构了风控技术框架
我们首先分析隐私计算承载着何种职能。
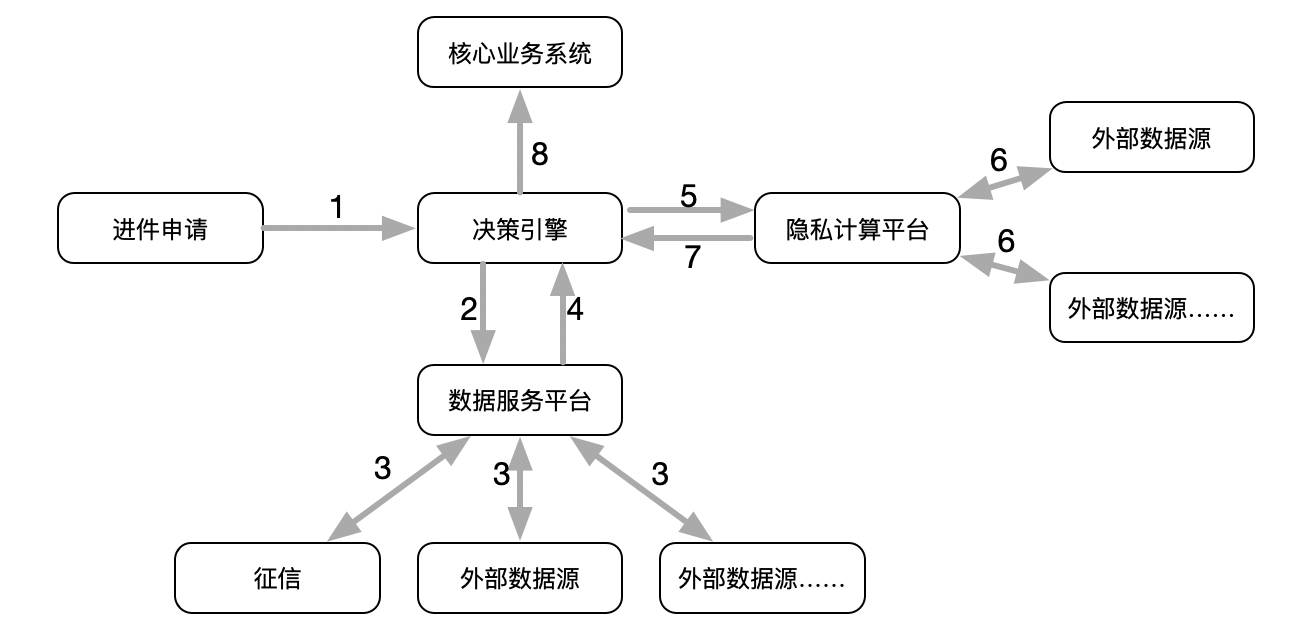
由于部分设计个人隐私的数据的价值必须通过隐私产品交互获得,且这些数据无法移出隐私产品,必须在隐私产品内进行模型训练和预测,因此隐私计算产品替代了决策引擎的计算模块和部分数据服务平台职能。
模型训练阶段还是事前、非实时的,与之前不同的是,银行需将从数据集市中提炼的样本(包含主键信息和银行端存量特征值)一同灌入隐私计算产品之中,在隐私产品中与不同数据源的节点互动迭代生成模型。需要强调的是,此时的成型模型不能移出,只能存放在隐私产品之中。
隐私行业所说的建模速度损耗就是指的该阶段,受算力和网络传输的影响,当前的隐私计算建模效率至少是明文状态的百倍。这还不包括从数据集市到隐私计算产品之间的传输环节。
模型预测(运行)时,由于银行接入了央行征信、百行征信等很多其它合规数据源(而这些数据源是明文差得的),因此还是不能绕开决策引擎和原有的数据服务平台。合意的做法是:还是将进件申请获得的客户主键信息推动至决策引擎,先由决策引擎通过数据服务平台,从央行征信等系统查得明文数据,从风控集市中查得银行存量数据标签后,与主键信息一起灌入隐私计算产品之中,在隐私产品中实现与三方隐私数据节点的交互,并一同导入成型模型中计算出结果。
由于隐私产品很难结合核心系统和进件前段系统进行个性化改造,因此将多个模型结果打包生成决策包的工作还需决策引擎承担。隐私计算平台要将计算得出的模型预测(模型运行)结果推给决策引擎,形成指令集后由决策引擎推送至核心系统及进件前端进行展示。
因此,调整后的风控技术架构见下图。与之前相比,合意的设计框架多了隐私计算平台这一支路。
隐私计算适合从简单、独立场景做切入
很多银行等金融机构采用的是统一风控平台架构,多年沉淀形成的风控信息技术架构远比上图刻画的复杂,对接的系统、个性化的接口包装复杂多样,牵一发而动全身,一旦改动,成本巨大。对于这些金融机构,统一风控平台已经纳入公司IT基础设施之中,对于引入隐私平台从而涉及的风控平台调整属于公司重大基础设施调整,这就要求隐私产品必须经过多年实践验证,足够安全与稳定后,通过统一招投标纳入金融机构集采名单,方能予以使用。从这一点讲,隐私计算进入银行等金融机构核心系统或基础设施还有很长的一段路要走。
比较现实的操作是:在小型业务场景中先行先试隐私计算,单独搭建整套风控框架和数据库,做到与统一风控平台基础设施的平行运行。为该业务场景建立单独的数据库,该数据库与银行数据中台或既有风控数据库联通,用于存放并向隐私产品提供提前抽取好的业务相关客户和特征标签,同时存储新生成的业务数据,及时同步至公司数据中台。

交钥匙隐私计算一体机的出厂配置
笔者历史文章曾经提及,隐私计算一体机的独有CPU或集成的GPU、FPGA会极大缓解隐私计算算力瓶颈,加之种种其它原因决定了一体机是隐私计算的必然发展方向之一。如果仅是如此,隐私计算一体机距离尽量减少银行开发调整的“交钥匙”工程还有不小差距。
前文提到,由于单独存放于数据库中的风控集市需要与决策引擎、隐私计算产品进行反复查询和读写,因此数据库对隐私计算产品的支持效率同样会影响建模效率,因此在一体机中集成进“可以大幅提升反复查询读写的内存式数据库”或“适应大吞吐量数据查询读写的分布式数据库”是必须要考虑的问题。
隐私计算一体机最好也要有决策引擎的集成方案。由于决策引擎涉及到对业务系统和进件前端的个性化改造与支持,这将是一个或有选择。决策引擎对核心系统和进件前端系统的个性化适配是在所难免的,要么,集成在一体机之中的隐私产品和数据库与银行业务已有的风控决策引擎做连接耦合,要么将决策引擎也集成在一体机之中,针对银行业务在核心系统及进件前端的个性化展示,将隐私产品的计算结果进行转换,并生成针对性决策包推送给核心系统。
综上,未来真正具备交钥匙能力的“隐私计算一体机”,不仅要承载隐私计算产品,还应该同时集成内存式/分布式数据库,用于存放单独支撑该业务的风控集市;同时,最好集成能够满足银行业务需求的决策引擎,能够直接对接业务核心系统以及进件前端系统,当然工程实施时少不了定制化开发耦合。
以上是针对银行新兴业务的“隐私计算一体机”交钥匙版本配置,笔者认为,只有当隐私厂商多做一点,真正做到不改变银行既有软硬件适配与架构调整,该隐私产品才真正具备“交钥匙”能力,如此距离大规模商用化发展之路也就不远了。
———————————————————
笔者个人公众号:高声谈,Inter-FinanceCow
邮箱:
欢迎读者多交流!
end

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}