隐私计算发展如火如荼,资本市场趋之若鹜。我们欣喜地看到,数据化程度较高的银行机构和线上金融机构纷纷开展了项目落地实践,成为隐私计算技术应用最为广泛,同时可能也是潜力最大的市场。
随着个人信息保护法执法落地,监管鼓励发酵和头部示范效应逐渐显现,未来将有越来越多的银行和金融机构尝试隐私计算工具。金融机构都会有哪些场景需要用到隐私计算技术?不同技术的应用特长是什么?金融机构如何选择?我们在此探讨一下。
银行业已落地项目
不完全统计,工商银行至少已经实施了基于多方安全计算的工银e生活营销项目、基于联邦学习的工银安盛健康险营销项目、基于联邦学习的企业贷中检测项目、基于多方安全计算的贷款资金流向跨行追踪项目、基于联邦学习的涉赌洗钱账户客群识别项目、北京分行与北京数据交易所的基于多方安全计算的信贷产品联合风控项目、广州分行与广州银联的基于多方安全计算溯源认证的跨境结算服务、山东分行基于多方数据学习的普惠信贷服务项目、珠海市分行与市政府基于多方安全计算的驾校资金监管项目等多个隐私计算项目,在多方安全计算、隐私加强联邦、可信执行环境三条技术路径全部部署了统一技术平台。
类似的案例还有:建设银行基于联邦学习的智能营销项目,农业银行基于隐私计算的普惠金融和联合风控项目,中国银行基于联邦学习的数据中台项目,交通银行基于多方安全计算的“惠民贷”联合风控项目、基于多方安全知识图谱计算的中小微企业融资服务项目、与银联总公司的基于多方安全计算的图像隐私保护产品和精准营销项目、与深圳政数局,光大集团基于多方安全计算的全辖子公司联合统计项目,重庆农商银行基于多方学习的涉农信贷服务项目,新网银行基于多方安全计算的小微企业智慧金融服务项目,华夏银行基于多方数据学习的小微融资风控项目,平安银行上海分行基于同态加密的“数据通”数据融合应用项目,南京银行基于多方安全计算的差异化营销平台,上海浦发银行杭州分行基于隐私计算技术的数据核验项目等,苏州银行基于隐私计算的普惠金融和联合风控项目。
隐私计算在金融业的可用场景
- 身份鉴权
包括二要素、三要素、四要素核验。在《隐私计算与个人信息保护的深层逻辑关系》一文中(笔者公号进门左转),我们探讨了个人信息保护法(简称个保法)的内在要求:去标识化是数据运营主体的基本操作,匿名化则不用遵循个保法要求。只是做到了去标识化,运营企业还需取得自然人对于“数据使用与交互所有主体的明确事前告知并授权”以及数据全生命周期的相关保护义务。鉴于很多保护动作的实施细则及执法尺度尚无参考,运营企业最好通过隐匿查询方式进行上述核验动作。
对于上述单向查询场景,查询方的最大诉求是不希望被查询方知晓查询内容并指向特定自然人,这便是去标识化的核心定义,也是隐匿查询的用武之地。
有多条技术路径都可以实现隐匿查询,如秘密共享、不经意传输、隐私信息检索等,使得数据不出域核验,杜绝数据缓存、数据泄漏、数据贩卖的可能性。
但当前的身份鉴权场景很少应用隐匿查询技术,原因有二:一是由于隐匿查询是查询方强诉求,不会对数据源厂商带来好处,还需调配资源部署隐私查询节点并增加了计算能耗,数据源厂商往往缺乏配合改造动力,很少部署隐私计算技术;二是明文身份鉴权方式下查询方类型、频次、查询内容等信息本身就是一类可供输出的价值数据源,如果使用隐匿查询技术,数据源厂商将不会再获得此类数据供给,反而损失了利益。
- 查询黑产与多头
在从事线上风控时,银行等金融机构必不可少要查询一些行业黑名单和多头借贷情况,相关查询结果有的直接用于拒绝策略,有的则纳入反欺诈或授信模型中。
与鉴权场景类似,类似单向信息查询场景同样会用到隐匿查询技术。不同之处是,黑产与多头数据源厂商没有身份鉴权厂商体量大、话语权强,因此隐匿查询技术应用更广泛一些。
金融机构在使用类似数据时,要尤其注意源头厂商获取数据时的合法性、是否充分告知以及获得授权,这是合作的前提条件。
- 联合风控与营销
之所以将联合风控与营销列为一类,是因为二者都是通过建立量化模型的方式进行决策支撑,只是因建模目的、数据体量、双方样本统计性态以及实施方对算法接受程度等因素的不同,而采用不同的模型算法及建模思路。
联合风控与营销的建模做法有多种,其中最常见的是数据源与需求建模方的合作,此时的数据源厂商不参与计算,只输出标签化数据字段,主要建模工作由需求方完成。这种合作模式也属于单向查询场景,因此通过隐匿查询技术可以解决。
除此以外,还有一个更重,但也更安全的方式:联邦学习。可能是因为双方标签均不方便出域,双方在各自模型基础上通过交换梯度与统计结果的方式合建一个性能更优的模型,而双方互不知晓对方模型与客户具体情况。
- 其他场景
从目前隐私计算在金融行业的落地项目看,还有一些其他的相对个性化场景需求。
场景一:跨公司主体之间的围绕个人客户维度的联合统计分析,比如一个金融集团下辖各公司客户间之间,或行业、企业联盟之间的联合统计。联合统计分析常见采用同态加密、不经意传输或秘密分享等安全协议予以实现。
场景二:跨主体的个人信息共享,比如行业联盟建立黑名单或客户多头信息共享平台,联盟参与者不希望泄露自己查询动机和客户隐私情况下,一边共享数据,一边查询使用数据。不同于单向查询,这一场景往往涉及多家参与主体和一家中心节点,需要采用双盲隐匿查询方案予以解决,底层技术可能会用到同态加密、秘密共享、不经意传输、隐私信息检索等技术。
场景三:特定客户行为监控,比如反洗钱监控、异常交易客户监控。通常情况下,需要结合外部数据对客户的特定行为特征或拓扑关系进行挖掘,该场景主要运用联邦学习予以实现。
隐私计算公司评估方法
方才提到的同一场景下会对应多个底层技术,是因为不同隐私计算供应商采取了不同的加密算法和协议均能实现了同一目的,这也对金融机构选择供应商提供了技术困难。
由于案例较少,不同技术路径之间的优劣分析目前缺少依据和结论,我们目前只能从宏观维度、定性地对隐私计算供应商进行评估。评估维度主要有:公司创始人团队背景与专业履历、已获行业认证情况、专利投资人行业口碑、隐私计算技术沉淀时间、技术人员是否超过100人、已接通的数据源情况(真正能够供数)、已有合作方专业口碑以及合作案例的类型及规模等。除此以外,可以重点了解供应商技术特长,结合不同技术的擅长领域做技术合理性的大致判断。比如,对于显然需要联合建模的场景,采购以联邦学习见长的供应商更为合理。
隐私计算测试方法
有些金融机构在采购前需要对不同厂商技术方案进行测试,测试目的主要有:安全性评估、效能损耗评估、模型效果评估。
如何评估科学有效,最理想的状态是:运用供应商已接通的数据源,在同一模型算法和加工逻辑下,将隐私计算的相关结果与明码状态结果进行对比分析,将不同供应商间隐私计算结果进行对比分析。但现实的困难有三:一是不同供应商接通的数据源差别较大,数据字段不同、模型不同会导致不同供应商之间的对比分析无法实现;二是当前的隐私计算公司对数据源的覆盖度普遍较低,很少能够提供真实接通的测试数据;三是产品安全性自证是行业难题,行业普遍没有解决思路。
因此,只能退而求其次追求隐私计算与明码状态下,建模效能和模型效果的损耗了。测试方案一般如此设计:
1、设立两台机器分别部署计算节点,一个模拟数据源方,一个模拟查询及建模方;
2、将在用模型、历史客户外采数据字段的查得结果部署在数据方计算节点上,将历史客户样本信息及内部数据字段部署在查询方计算节点上;
3、使用供应商的隐私计算工具,按照在用模型的数据加工、建模流程重跑一遍,记录各环节性能占用、耗费时间、模型结果和性能;
4、将上述结果与明文环境下结果进行对比分析。
已获认证公司产品名录
目前我国隐私计算相关技术认证有:中国信息通信研究院、国家金融科技测评中心(信用卡检测中心)、北京国家金融科技认证中心、中国金融认证中心(CFCA)。从开展认证业务时间长短及市场认可情况看,主要是前两家认证机构。
国家金融科技测评中心(信用卡检测中心)过检名单
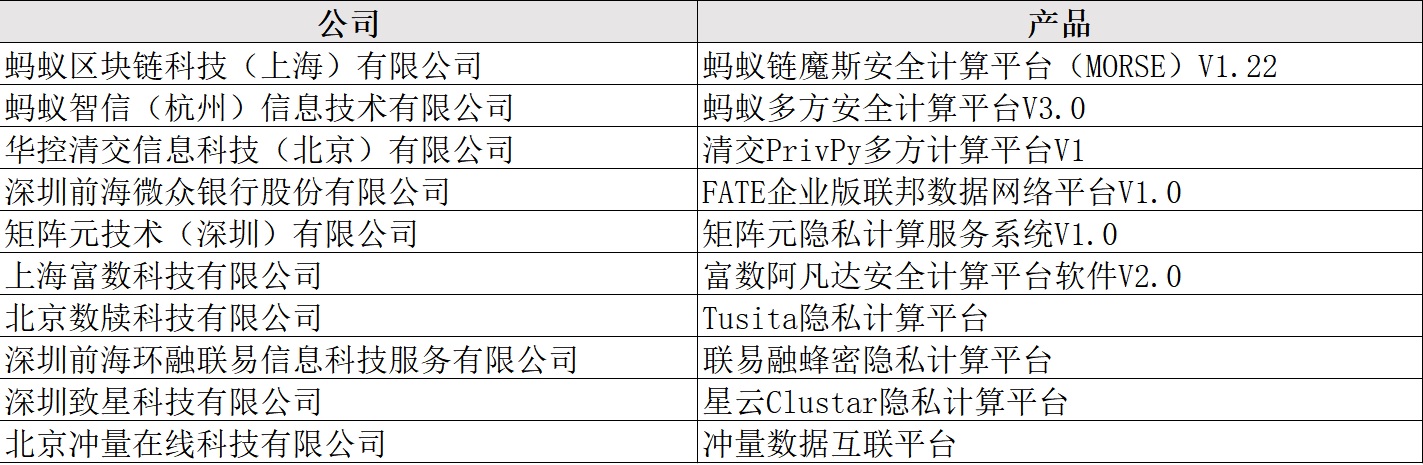
信通院多方安全计算安全专项评测过检名单

信通院联邦学习安全专项评测过检名单
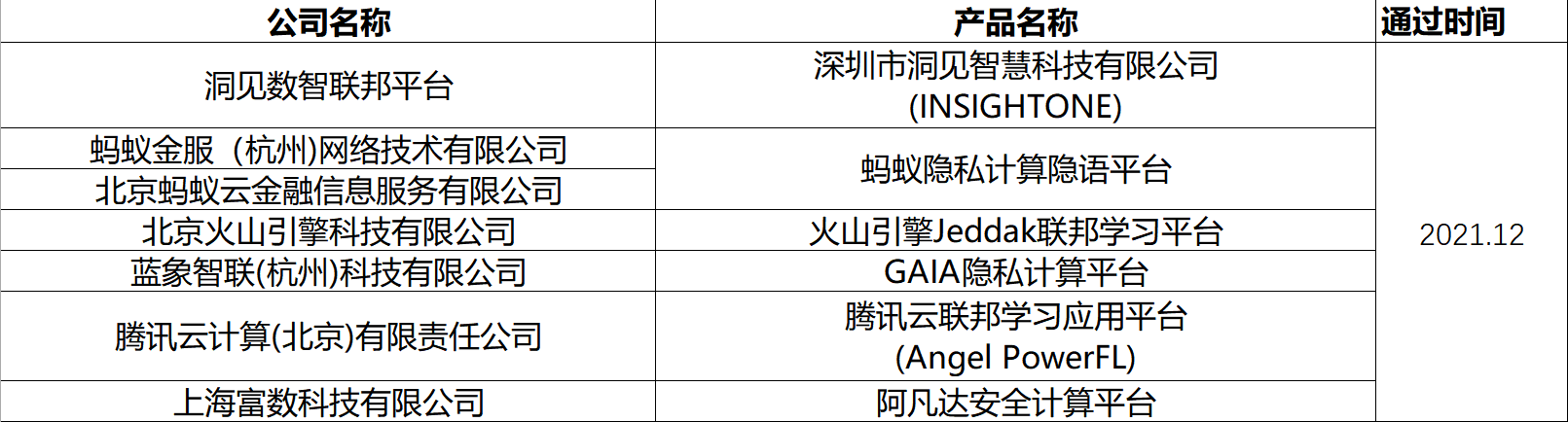
信通院多方安全计算性能专项评测过检名单
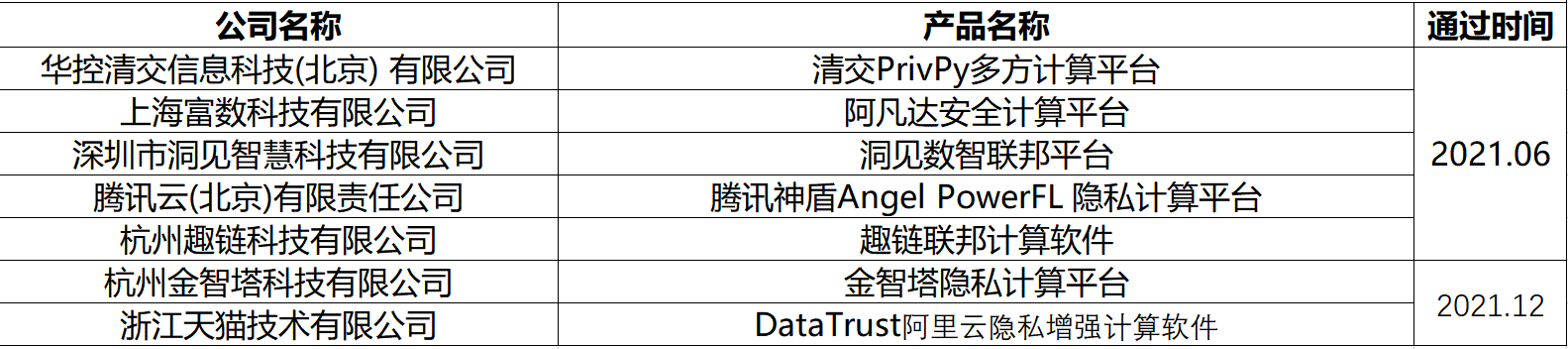
信通院联邦学习性能专项评测过检名单
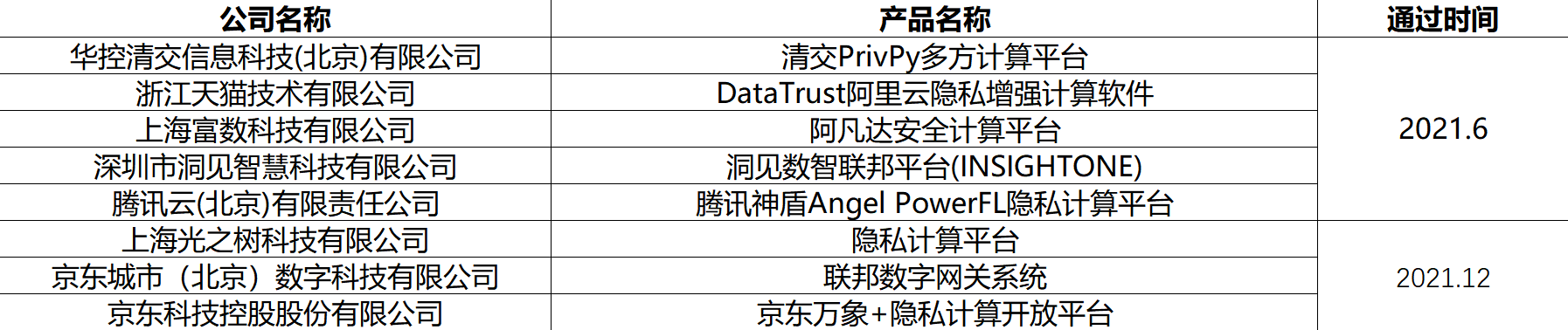
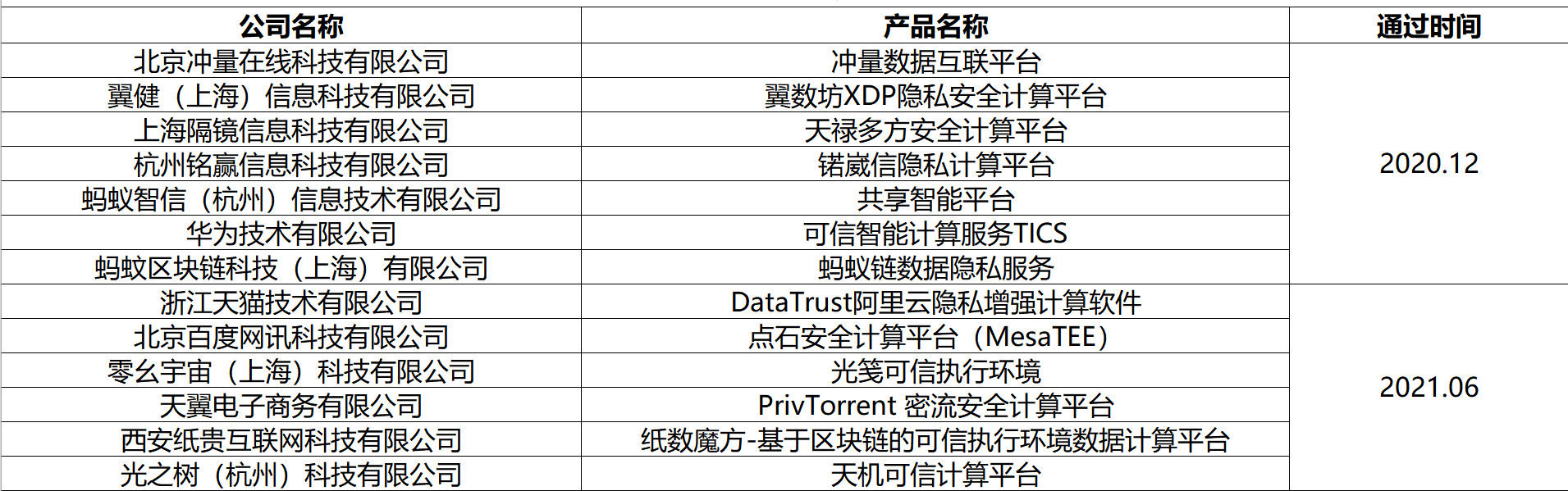
信通院可信执行环境基础能力专项评测过检名单
———————————————————
笔者个人公众号:高声谈,Inter-FinanceCow
邮箱:
欢迎读者多交流!

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}